
☆ Yσɠƚԋσʂ ☆
- 13.2K Posts
- 13.5K Comments


 3·1 hour ago
3·1 hour agoSame, and rice definitely makes sense if you have access to a local source of water which we know is possible on the moon. Next decade will be exciting.
Knowing how China plays the long game these could be early experiments to see if they can start growing food at the moon base China is planning. That would cut down costs immensely for long term habitation.
If China managed to bootstrap food production and some industry the base could be largely self sufficient.




 5·23 hours ago
5·23 hours agothat checks outs
 141·1 day ago
141·1 day agoyou don’t need to keep proving that you’re a sick fuck you know
these people can’t help but tell on themselves
Imagine being such an utter scumbag to cheer for attacks on civilians. As the saying goes, scratch a liberal…

 41·1 day ago
41·1 day agoI mean it’s probably the most secure way to send data between two devices.
which is a big reason why the US was so obsessed with destabilizing Afghanistan
 3·1 day ago
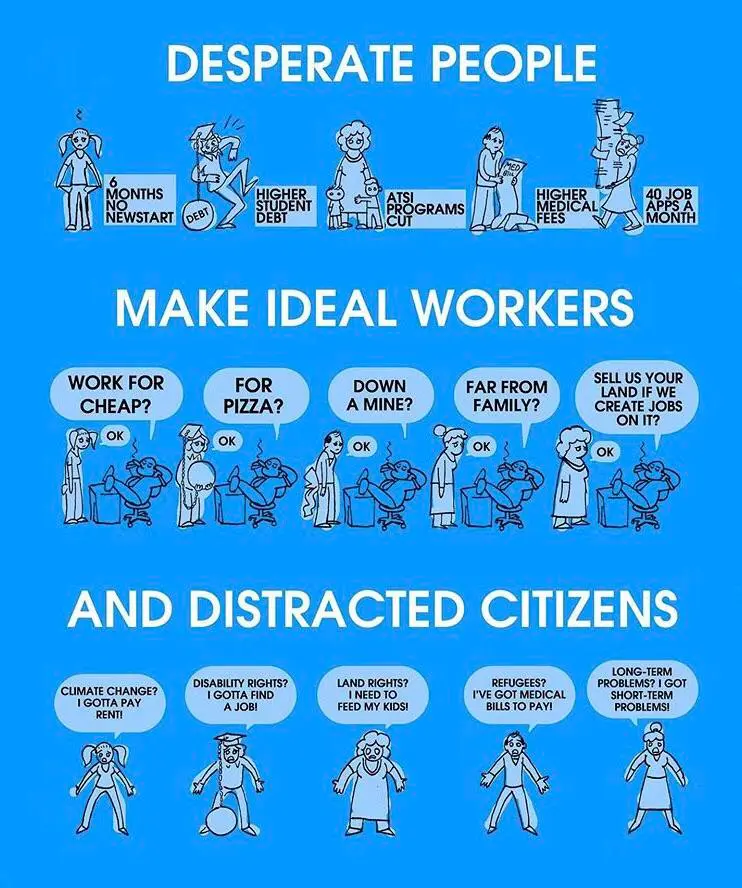
3·1 day agoRight, when people are forced to work that’s a problem, but people having an option to do so is a positive.
yeah seems like it might not be out yet
Most people actually want to be productive. If you’ve ever been sick and unable to do anything for a prolonged period of time, you’d know how excruciating it is. There’s a big difference between being productive and being exploited.
do elaborate
what is up with that garbage comment?
Yeah makes sense, I really love how solar tends to be complimentary with environmental preservation. As the world gets hotter, creating more shaded areas will be useful.


haha Chinese engineers also figured out that putting solar panels over the high way instead of having them being destroyed by traffic works a lot better :) https://www.innovationnewsnetwork.com/solar-panel-roofs-on-highways-could-slash-global-carbon-emissions/49928/
{kind=link}
{kind=link}
{kind=link}
that’s certainly what it looks like