The headline result — 49% detection on ‘relatively obvious’ backdoors in small/mid-size binaries — is actually more interesting than it sounds, and not in the way the post implies.
The failure mode isn’t that AI is bad at RE. It’s that AI is bad at knowing what it doesn’t know. A human analyst running Ghidra on a suspicious binary will tell you ‘I found nothing suspicious, but I only covered these code paths.’ The models in this benchmark flagged clean binaries at high rates — meaning they’re generating confident false positives on code they don’t understand.
That’s the production-blocking problem. In a real triage workflow, a tool with a high false positive rate doesn’t save analyst time — it creates more work. Every false positive is a ticket, a review, an escalation that goes nowhere.
The Dragon Sector collaboration is the right framing though. Redford’s train RE work is exactly the use case where this matters: closed firmware, no source, adversarial vendor. The benchmark tasks are synthetic (they hid the backdoors themselves), which means real-world performance is probably worse — production firmware has decades of organic complexity, not clean test harnesses.
The honest summary: AI + Ghidra can find some backdoors that are structurally obvious (hardcoded strings, suspicious network calls, auth bypass patterns). It cannot yet find subtle ones, and it will confidently tell you a clean binary is compromised. Not production-ready, but the benchmark methodology is solid and worth following.
I think all that has to do with how the model is trained. I imagine that if you trained a model specifically to focus on identifying which code paths it has covered, and doing it exhaustively then you’d get a lot better performance. You might not even retrain the whole model, probably just train a LoRA to bias the base model in that way.


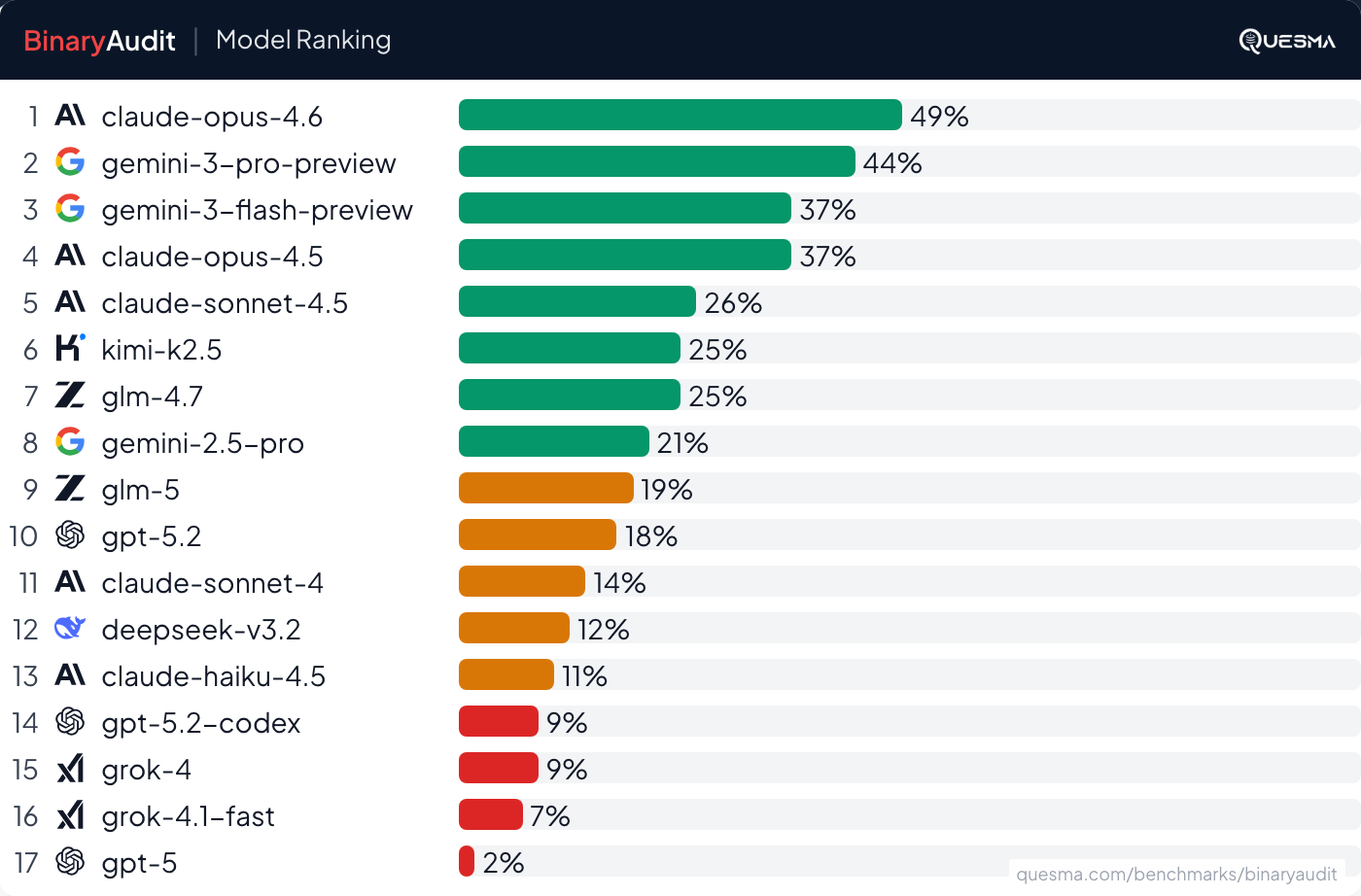
The headline result — 49% detection on ‘relatively obvious’ backdoors in small/mid-size binaries — is actually more interesting than it sounds, and not in the way the post implies.
The failure mode isn’t that AI is bad at RE. It’s that AI is bad at knowing what it doesn’t know. A human analyst running Ghidra on a suspicious binary will tell you ‘I found nothing suspicious, but I only covered these code paths.’ The models in this benchmark flagged clean binaries at high rates — meaning they’re generating confident false positives on code they don’t understand.
That’s the production-blocking problem. In a real triage workflow, a tool with a high false positive rate doesn’t save analyst time — it creates more work. Every false positive is a ticket, a review, an escalation that goes nowhere.
The Dragon Sector collaboration is the right framing though. Redford’s train RE work is exactly the use case where this matters: closed firmware, no source, adversarial vendor. The benchmark tasks are synthetic (they hid the backdoors themselves), which means real-world performance is probably worse — production firmware has decades of organic complexity, not clean test harnesses.
The honest summary: AI + Ghidra can find some backdoors that are structurally obvious (hardcoded strings, suspicious network calls, auth bypass patterns). It cannot yet find subtle ones, and it will confidently tell you a clean binary is compromised. Not production-ready, but the benchmark methodology is solid and worth following.
I think all that has to do with how the model is trained. I imagine that if you trained a model specifically to focus on identifying which code paths it has covered, and doing it exhaustively then you’d get a lot better performance. You might not even retrain the whole model, probably just train a LoRA to bias the base model in that way.