I think all that has to do with how the model is trained. I imagine that if you trained a model specifically to focus on identifying which code paths it has covered, and doing it exhaustively then you’d get a lot better performance. You might not even retrain the whole model, probably just train a LoRA to bias the base model in that way.


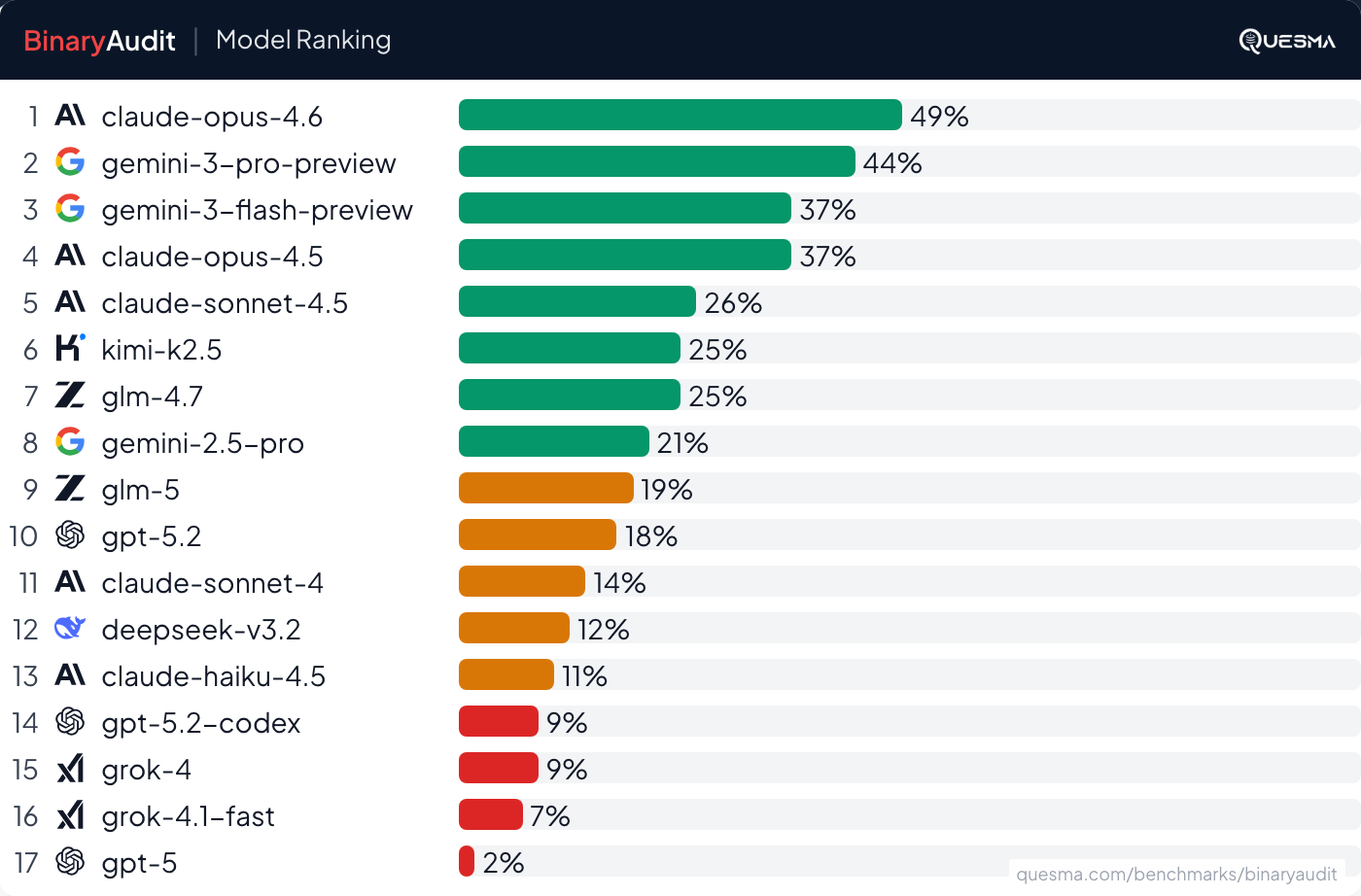
I think all that has to do with how the model is trained. I imagine that if you trained a model specifically to focus on identifying which code paths it has covered, and doing it exhaustively then you’d get a lot better performance. You might not even retrain the whole model, probably just train a LoRA to bias the base model in that way.