

3·
2 months agoQOI is just a format that’s easy for a programmer to get their head around.
It’s not designed for everyday use and hardware optimization like jpeg-xl is.
You’re most likely to see QOI in homebrewed game engines.
QOI is just a format that’s easy for a programmer to get their head around.
It’s not designed for everyday use and hardware optimization like jpeg-xl is.
You’re most likely to see QOI in homebrewed game engines.
Are you not made primarily of water?
The syntax is only difficult to read in their example.
I fixed their example here: https://programming.dev/comment/12087783
I fixed it for you (markdown tables support padding to make them easy to read):
| markdown | table |
|---|---|
| x | y |
|markdown|table|
|--------|-----|
|x |y |
Chromium had it behind a flag for a while, but if there were security or serious enough performance concerns then it would make sense to remove it and wait for the jpeg-xl encoder/decoder situation to change.
It baffles me that someone large enough hasn’t gone out of their way to make a decoder for chromium.
The video streaming services have done a lot of work to switch users to better formats to reduce their own costs.
If a CDN doesn’t add it to chromium within the next 3 years, I’ll be seriously questioning their judgement.
I’m under the impression that there’s two reasons we don’t have it in chromium yet:
Google already wrote the wuffs language which is specifically designed to handle formats in a fast and safe way but it looks like it only has one dedicated maintainer which means it’s still stuck on a bus factor of 1.
Honestly, Google or Microsoft should just make a team to work on a jpg-xl library in wuffs while adobe should make a team to work on a jpg-xl library in rust/zig.
That way everyone will be happy, we will have two solid implementations, and they’ll both be made focussing on their own features/extensions first so we’ll all have a choice among libraries for different needs (e.g. browser lib focusing on fast decode, creative suite lib for optimised encode).
Who is this article for?
Firstly, it’s basically just a repost of existing info from the mozilla article but now with ads.
Secondly, the puppeteer team left years ago to work on playwright which is now the better product, which also supports firefox through the webdriver-bidi standard…
So now I’m wondering… just who was this article for?
None of what you mentioned is actually about politics, it’s just a list of outrage-bait
I use git log --graph --all --remotes --oneline whenever I need to shell into another computer, but it’s still too barebones for regular use.
What specifically do you think is legacy in that comparison? The coloring? The horizontal layout? The whitespace?
Note: I’ve changed the first link from https://github.com/cxli233/FriendsDontLetFriends/network to https://github.com/zed-industries/zed/network. Still the same view, but just a different repo to highlight the problems
I’ll stop here at 10 reasons (or more if you count the dot points), otherwise I’ll be here all day.
The network view lays out forks and their branches, not only [local]/[local+1-remote] branches.
Yes, but the others can do that while still being usable.
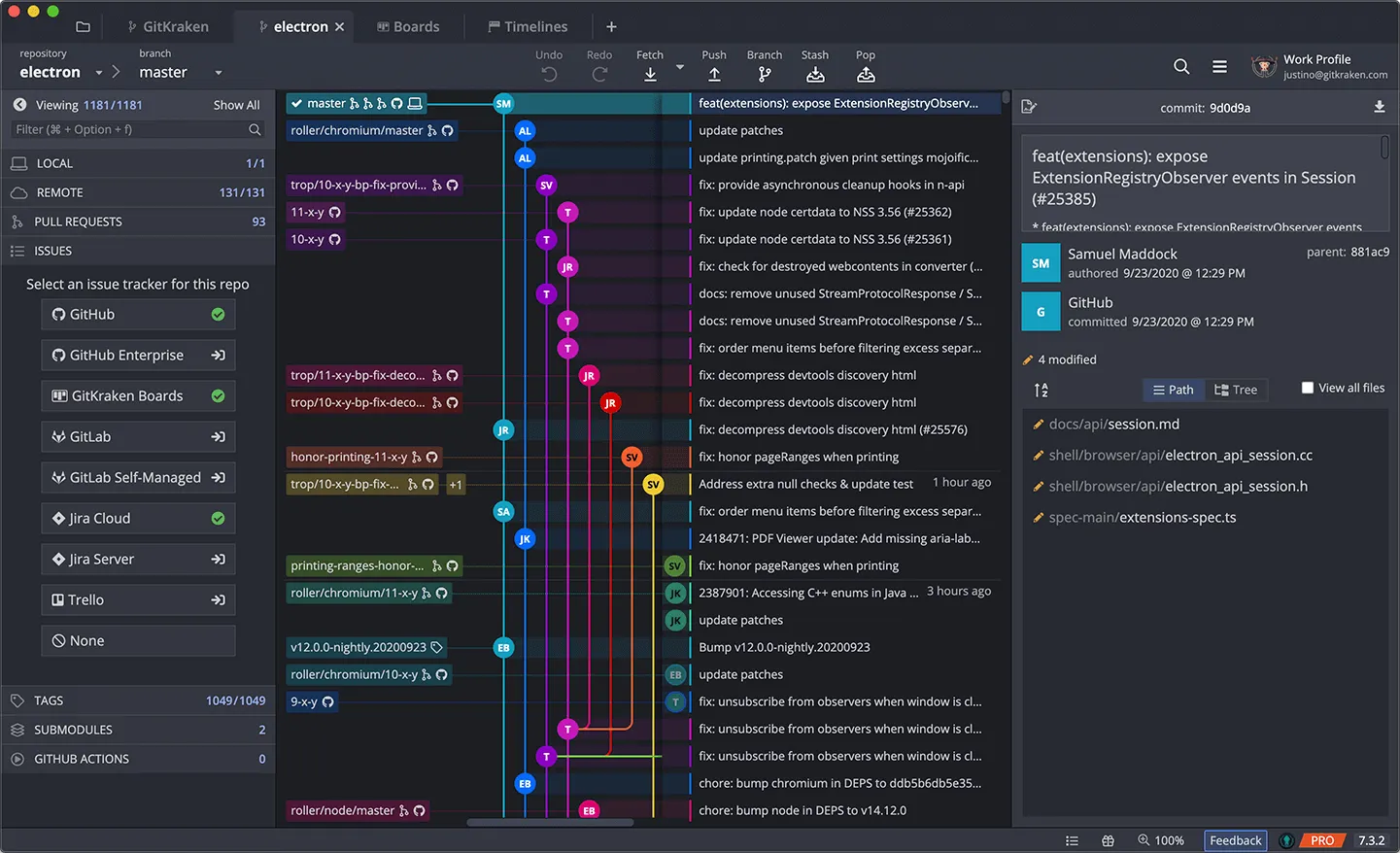
I don’t know what IDE that miro screenshot is from. […]
It’s gitkraken
[…] But I see it as wasteful and confusing. The author initials are useless and wasteful, picking away focus. The branch labels are far off from the branch heads. […]
The picture doesn’t do it justice, it’s not a picture, it’s an interactive view.
You can resize things, show/hide columns, filter values in columns to only show commits with certain info (e.g. Ignore all dependabot commits), etc… Here’s an example video.
[…]The coloring seems confusing.
You can customise all that if you want.
The first link is a totally different purpose than the second two.
The first link is going to there because that’s the only graph view that github has.
I’ve got to say, seeing this:
https://github.com/zed-industries/zed/network
instead of something like this:
https://fork.dev/blog/posts/collapsible-graph/
or this:
https://miro.medium.com/v2/resize:fit:4800/format:webp/0*60NIVdYj2f5vETt2.png
feels pretty damn legacy to me.
I’d recommend removing as many variables as possible.
Try getting a single html page to work (no mongoose, no preact, no vite, no tailwind).
If you can’t get that to work, then no amount of tinking in preact/vite/tailwind/mongoose will help you.
Once you have a single page running, you can look at the next steps:
For scripting: try plain js, then js + mongoose, then preact + mongoose. If a step fails, rely on the step before it.
For styling: try plain css, then a micro css framework that doesn’t require a build step (e.g. https://purecss.io/, https://picocss.com/), then tailwind if you really want to try messing around with vite again.
There are some tools/libraries that act as a front-layer over regex.
They basically follow the same logic as ORMs for databases:
But there’s no common standard, and it’s always language specific.
Personally I think using linters is the best option since it will highlight the footguns and recommend simpler regexes. (e.g. Swapping [] for \d)
At least once every few days while coding, usually to do one of the following:
Select multiple things in the same file at the same time without needing to click all over the place
Normally I use multicursor keyboard shortcuts to select what I want and for the trickier scenarios there are also commands to go through selections one at a time so you can skip certain matches to end up with only what you want.
But sometimes there are too many false matches that you don’t want to select by hand and that’s where regex comes in handy.
For instance, finding:
… which can be easily done by searching for a word that doesn’t include a letter immediately before or immediately after: e.g. \Wtest\W.
Search for things across all files that come back with too many results that aren’t relevant
Basically using the same things above.
Finding something I already know makes a pattern. Like finding all years: \d{4}, finding all versions: \d+\.\d+\.\d+, finding random things that a linter may have missed such as two empty lines touching each other: \n\s*\n\s*\n, etc…
There’s a whole bunch of pull requests and issues sitting there for a start.
Personally I’d also update the example in the readme and set an engine value in the package.json file.

Are you using the group policy editor?
Why would I leave windows if Linux isn’t offering anything better?
Because Linux offers an ad-free experience, whereas Windows offers a free ads experience.
Have you considered the Required<T> generic?
https://www.typescriptlang.org/docs/handbook/utility-types.html#requiredtype

{kind=link}
This doesn’t seem overly useful.
It’s a list taken out of a bunch of books with no regard for how something can be the best path in one language and a smell in another language.
Look at this page for example: https://luzkan.github.io/smells/imperative-loops
It suggests using functional loop methods (
.map(),.reduce(),.filter()) instead of using imperative loops (for,for in,for each) but completely disregards the facts that imperative loops also have access to thebreak,continue, andreturnkeywords to improve performance.For example: If I have an unsorted list of 1000 cars which includes a whole bunch of information per car (e.g. color, year manufactured, etc…), and I want to know if there were any cars were manufactured before the year 1980, I can run an imperative loop through the list and early return true if I find one, and only returning false if I haven’t found one by the end of the list.
If the third car was made in 1977, then I have only iterated through 3 cars to find my answer.
But if I were to try this with only functional loops, I would have to iterate through all 1000 cars before I had my answer.
A website with blind rules like this is going to lead to worse code.